
ODBC Database Monitoring using ActiveXperts
ActiveXperts solution to monitor ODBC
ActiveXperts Network Monitor uses ODBC to check availability of a variety of databases. Most major database systems support ODBC, such as: Microsoft SQL Server, Microsoft Access, Microsoft Excel, Oracle, FoxPro, Paradox, SyBase, Informix, OpenIngres, InterBase, Progress, IBM LANDP, DB2 and AS/400. You must configure ODBC (from the Control Panel on the server where ActiveXperts Network Monitor is running on) before ActiveXperts Network Monitor can check ODBC compliant databases.
An ODBC check requires the following parameters:
- ODBC DSN Name - the ODBC DSN (Data Source Name). This DSN entry must be configured on the server where the ActiveXperts Network Monitor service is running;
- Username/Login - credentials required to access the database;
- Password - credentials required to access the database.
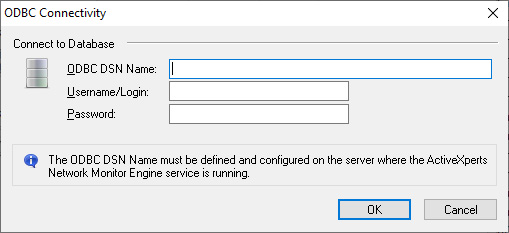
ActiveXperts Network Monitor ODBC check
About ODBC
Open Database Connectivity (ODBC) is a widely accepted application programming interface (API) for database access. It is based on the Call-Level Interface (CLI) specifications from X/Open and ISO/IEC for database APIs and uses Structured Query Language (SQL) as its database access language. ODBC is designed for maximum interoperability;that is, the ability of a single application to access different database management systems (DBMSs) with the same source code. Database applications call functions in the ODBC interface, which are implemented in database-specific modules called drivers. The use of drivers isolates applications from database-specific calls in the same way that printer drivers isolate word processing programs from printer-specific commands. Because drivers are loaded at run time, a user only has to add a new driver to access a new DBMS; it is not necessary to recompile or relink the application.
Why Was ODBC Created?
Historically, companies used a single DBMS. All database access was done either through the front end of that system or through applications written to work exclusively with that system. However, as the use of computers grew and more computer hardware and software became available, companies started to acquire different DBMSs. The reasons were many: People bought what was cheapest, what was fastest, what they already knew, what was latest on the market, what worked best for a single application. Other reasons were reorganizations and mergers, where departments that previously had a single DBMS now had several.
The issue grew even more complex with the advent of personal computers. These computers brought in a host of tools for querying, analyzing, and displaying data, along with a number of inexpensive, easy-to-use databases. From then on, a single corporation often had data scattered across a myriad of desktops, servers, and minicomputers, stored in a variety of incompatible databases, and accessed by a vast number of different tools, few of which could get at all of the data. The final challenge came with the advent of client/server computing, which seeks to make the most efficient use of computer resources. Inexpensive personal computers (the clients) sit on the desktop and provide both a graphical front end to the data and a number of inexpensive tools, such as spreadsheets, charting programs, and report builders. Minicomputers and mainframe computers (the servers) host the DBMSs, where they can use their computing power and central location to provide quick, coordinated data access. How then was the front-end software to be connected to the back-end databases?
A similar problem faced independent software vendors (ISVs). Vendors writing database software for minicomputers and mainframes were usually forced to write one version of an application for each DBMS or write DBMS-specific code for each DBMS they wanted to access. Vendors writing software for personal computers had to write data access routines for each different DBMS with which they wanted to work. This often meant a huge amount of resources were spent writing and maintaining data access routines rather than applications, and applications were often sold not on their quality but on whether they could access data in a given DBMS.
What both sets of developers needed was a way to access data in different DBMSs. The mainframe and minicomputer group needed a way to merge data from different DBMSs in a single application, while the personal computer group needed this ability as well as a way to write a single application that was independent of any one DBMS. In short, both groups needed an interoperable way to access data; they needed open database connectivity.
What Is ODBC?
Many misconceptions about ODBC exist in the computing world. To the end user, it is an icon in the Microsoft Windows Control Panel. To the application programmer, it is a library containing data access routines. To many others, it is the answer to all database access problems ever imagined.
First and foremost, ODBC is a specification for a database API. This API is independent of any one DBMS or operating system; although this manual uses C, the ODBC API is language-independent. The ODBC API is based on the CLI specifications from X/Open and ISO/IEC. ODBC 3.x fully implements both of these specifications, earlier versions of ODBC were based on preliminary versions of these specifications but did not fully implement them, and adds features commonly needed by developers of screen-based database applications, such as scrollable cursors.
The functions in the ODBC API are implemented by developers of DBMS-specific drivers. Applications call the functions in these drivers to access data in a DBMS-independent manner. A Driver Manager manages communication between applications and drivers.
Although Microsoft provides a Driver Manager for computers running Microsoft Windows NT Server/Windows 2000 Server, Microsoft Windows NT Workstation/Windows 2000 Professional, and Microsoft Windows� 95/98, has written several ODBC drivers, and calls ODBC functions from some of its applications, anybody can write ODBC applications and drivers. In fact, the vast majority of ODBC applications and drivers available for computers running Windows NT Server/Windows 2000 Server, Windows NT Workstation/Windows 2000 Professional, and Windows 95/98 are produced by companies other than Microsoft. Furthermore, ODBC drivers and applications exist on the Macintosh and a variety of UNIX platforms.
To help application and driver developers, Microsoft offers an ODBC Software Development Kit (SDK) for computers running Windows NT Server/Windows 2000 Server, Windows NT Workstation/Windows 2000 Professional, and Windows 95/98 that provides the Driver Manager, installer DLL, test tools, and sample applications. Microsoft has teamed with Visigenic Software to port these SDKs to the Macintosh and a variety of UNIX platforms.
It is important to understand that ODBC is designed to expose database capabilities, not supplement them. Thus, application writers should not expect that using ODBC will suddenly transform a simple database into a fully featured relational database engine. Nor are driver writers expected to implement functionality not found in the underlying database. An exception to this is that developers who write drivers that directly access file data (such as data in an Xbase file) are required to write a database engine that supports at least minimal SQL functionality. Another exception is that the ODBC component of the Microsoft Data Access Components (MDAC) SDK provides a cursor library that simulates scrollable cursors for drivers that implement a certain level of functionality.
Applications that use ODBC are responsible for any cross-database functionality. For example, ODBC is not a heterogeneous join engine, nor is it a distributed transaction processor. However, because it is DBMS-independent, it can be used to build such cross-database tools.
ODBC and the Standard CLI
ODBC aligns with the following specifications and standards that deal with the Call-Level Interface (CLI). (The ODBC features are a superset of each of these standards.)
- The X/Open CAE Specification "Data Management: SQL Call-Level Interface (CLI)"
- ISO/IEC 9075-3:1995 (E) Call-Level Interface (SQL/CLI)
As a result of this alignment, the following are true:
- An application written to the X/Open and ISO CLI specifications will work with an ODBC 3.x driver or a standards-compliant driver when it is compiled with the ODBC 3.x header files and linked with ODBC 3.x libraries, and when it gains access to the driver through the ODBC 3.x Driver Manager.
- A driver written to the X/Open and ISO CLI specifications will work with an ODBC 3.x application or a standards-compliant application when it is compiled with the ODBC 3.x header files and linked with ODBC 3.x libraries, and when the application gains access to the driver through the ODBC 3.x Driver Manager. (For more information, see "Standards-Compliant Applications and Drivers".
The Core interface conformance level encompasses all the features in the ISO CLI and all the nonoptional features in the X/Open CLI. Optional features of the X/Open CLI appear in higher interface conformance levels. Because all ODBC 3.x drivers are required to support the features in the Core interface conformance level, the following are true:
- An ODBC 3.x driver will support all the features used by a standards-compliant application.
- An ODBC 3.x application using only the features in ISO CLI and the nonoptional features of the X/Open CLI will work with any standards-compliant driver.
In addition to the call-level interface specifications contained in the ISO/IEC and X/Open CLI standards, ODBC implements the following features. (Some of these features existed in versions of ODBC prior to ODBC 3.x.)
- Multirow fetches by a single function call
- Binding to an array of parameters
- Bookmark support including fetching by bookmark, variable-length bookmarks, and bulk update and delete by bookmark operations on discontiguous rows
- Row-wise binding
- Binding offsets
- Support for batches of SQL statements, either in a stored procedure or as a sequence of SQL statements executed through SQLExecute or SQLExecDirect
- Exact or approximate cursor row counts
- Positioned update and delete operations and batched updates and deletes by function call (SQLSetPos)
- Catalog functions that extract information from the information schema without the need for supporting information schema views
- Escape sequences for outer joins, scalar functions, datetime literals, interval literals, and stored procedures
- Code-page translation libraries
- Reporting of a driver's ANSI-conformance level and SQL support
- On-demand automatic population of implementation parameter descriptor
- Enhanced diagnostics and row and parameter status arrays
- Datetime, interval, numeric/decimal, and 64-bit integer application buffer types
- Asynchronous execution
- Stored procedure support, including escape sequences, output parameter binding mechanisms, and catalog functions
- Connection enhancements including support for connection attributes and attribute browsing